Google Imagen is the brand new AI text-to-image generator on the market. It has not been launched within the public area. However, whereas asserting the brand new AI mannequin, the corporate has shared the analysis paper, a benchmarking instrument referred to as Drawbench to attract goal comparisons with Imagen’s opponents, and a few wacky photographs to your subjective pleasure. It additionally sheds mild on the potential harms of this tech.
Google Imagen: Right here’s how a text-to-image-model works
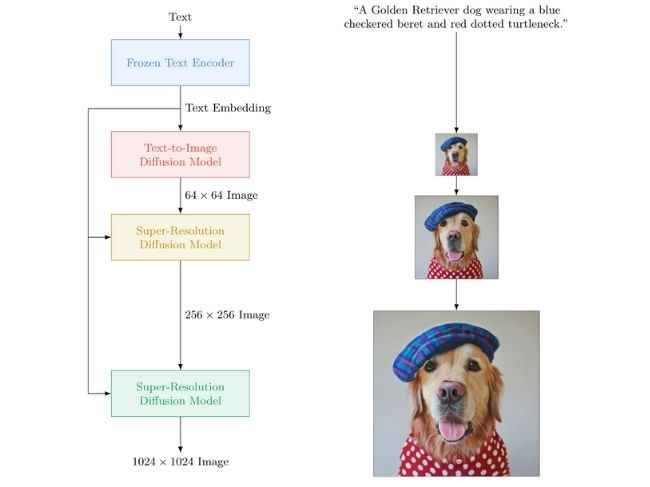
The thought is that you just say what you need the AI picture generator to conjure up and it does precisely that.
The pictures proven off by Google are more than likely the most effective of the lot and for the reason that precise AI instrument isn’t accessible by most of the people, we recommend you are taking the outcomes and claims with a grain of salt.
Regardless, Google is happy with Imagen’s efficiency and maybe why it has launched a benchmark for AI text-to-image fashions referred to as DrawBench. For what it’s price, the graphs by Google reveal how a lot of a lead Imagen has over the options like OpenAI’s Dall-E 2.
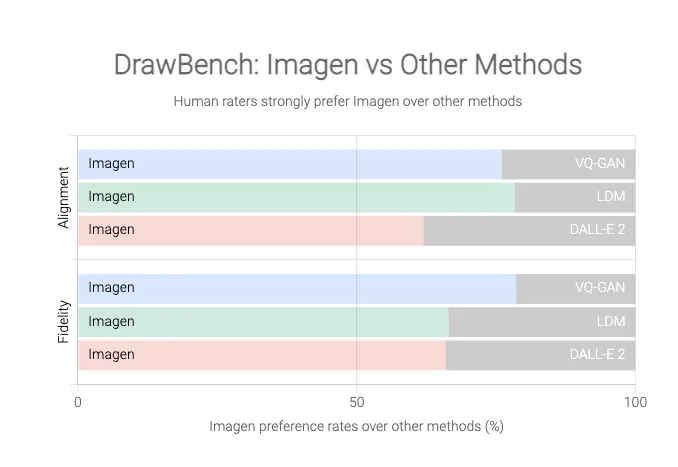
Now, similar to Open AI’s answer or for that matter, any comparable purposes have intrinsic flaws, that’s they’re liable to disconcerting outcomes.
Identical to ‘affirmation bias’ in people, which is our tendency to see what we imagine and imagine what we see, AI fashions that filter in massive quantities of information may also fall for these biases. That is again and again confirmed to be an issue with text-to-image turbines. So will Google’s Imagen be any completely different?
In Google’s personal phrases, these AI fashions encode “a number of social biases and stereotypes, together with an total bias in the direction of producing photographs of individuals with lighter pores and skin tones and a bent for photographs portraying completely different professions to align with Western gender stereotypes”.
The Alphabet firm may at all times filter out sure phrases or phrases and feed good datasets. However with the dimensions of information that these machines work on, not every thing might be sifted via, or not all kinks might be ironed out. Google admits to this by telling that “[T]he massive scale information necessities of text-to-image fashions […] have led researchers to rely closely on massive, principally uncurated, web-scraped dataset […] Dataset audits have revealed these datasets are inclined to replicate social stereotypes, oppressive viewpoints, and derogatory, or in any other case dangerous, associations to marginalized id teams.”
In order Google says, Imagen “isn’t appropriate for public use presently”. If and when it’s obtainable, let’s attempt saying to it, “Hey Google Imagen there isn’t any heaven. It is simple when you attempt. No hell under us. Above us, solely sky”.
As for different information, opinions, characteristic tales, shopping for guides, and every thing else tech-related, maintain studying Digit.in.














{kind=link}